+91-741-507-2700
Performance Analysis of Multithreaded Renderer
The renderer of a game engine is often a performance bottleneck from the CPU side. Adding multithreading to the rendering step is an effective means to address the performance issue without losing content details. The primary factors affecting multi-threaded rendering performance are analyzed, and the relevant optimization methods are explored as well.
Role
Graphics Programmer
Game Engine
Personal Phoenix Engine
Platform
PC (Windows)
Development Time
Ongoing, 5 Months, 2020
Team Size
Solo Developer

Contents
-
Current Progress Demonstration
-
Screenshots
-
Goals, Features and Even Better if
-
Dynamic Directional Light & Spot Light Shadow Maps
-
Job System, Worker Threads and Atomic Mutex
-
3-D Billboarded Particles
-
Particle Optimizations, Limitations and Decomposition Models
-
Other Features
-
Multithreading Models, Profiling, Tracking Memory Leaks and Data Dumping
-
Development Insights and Deep Learning
-
Post Mortem
Current Progress Demonstration
Screenshots



What did I plan to accomplish?
In simple terms - Rendering more objects on screen. High fidelity graphics are a big topic of interest for most hardcore gamers ,hence models and particles effects with the augmented realism of lighting with shadows were added to give a greater sense of depth to our scene. Understanding the intricacies of synchronization problem between multiple threads and between update and render loop.
What the artifact currently features?
-
Multiple Directional Light and Spotlight Shadows
-
CPU side Multithreaded 3D Billboarded Particle System
-
Multithreaded View Frustum Culling
What would I do to make it better?
-
Find more spots for parallelization
-
Add transparency to the particles and GPU instantiated particles
-
Implement 4-Split Cascaded shadow maps and scene graphs
Dynamic Directional Light & Spot Light Shadow Maps
-
Supports Multiple Spot Light and directional shadow casting lights.
-
Shadow casting on any light source can be toggled at runtime via the UI.
-
Non shadow casting Point lights are also supported with options to update various light parameters on the lights at runtime via the UI.
-
The purpose of dynamic shadows here is to serve towards enhancing the bottleneck in the performance of the rendering engine and explore optimization techniques.
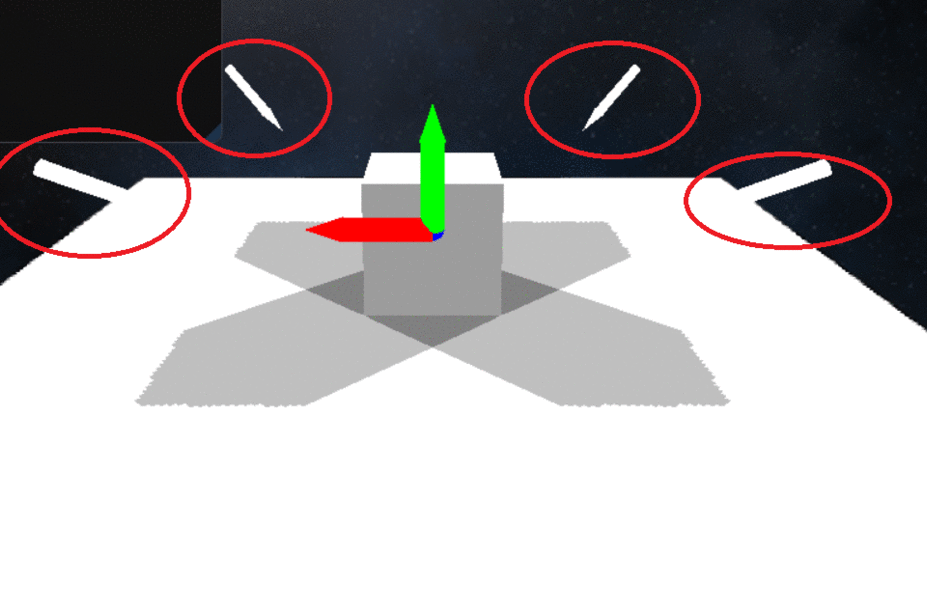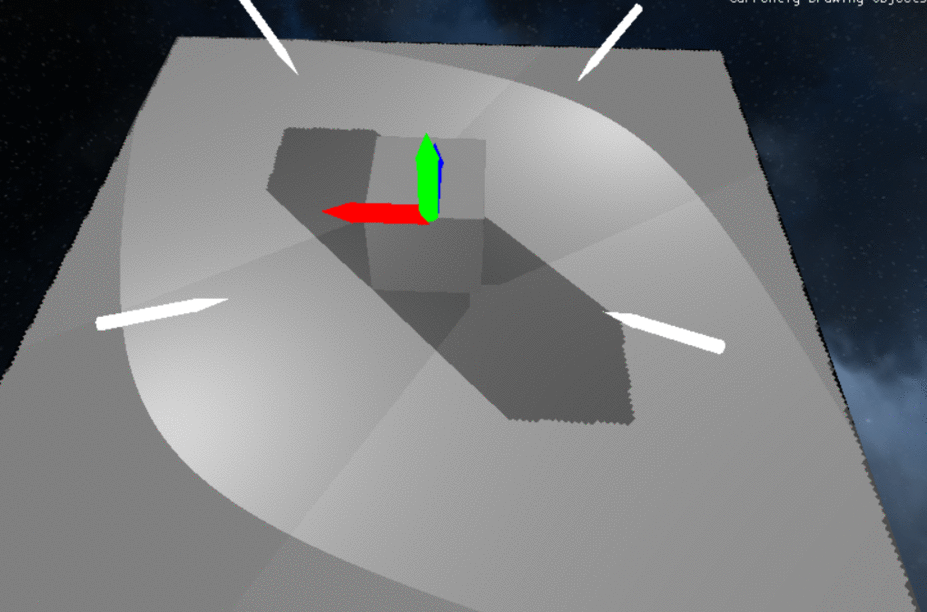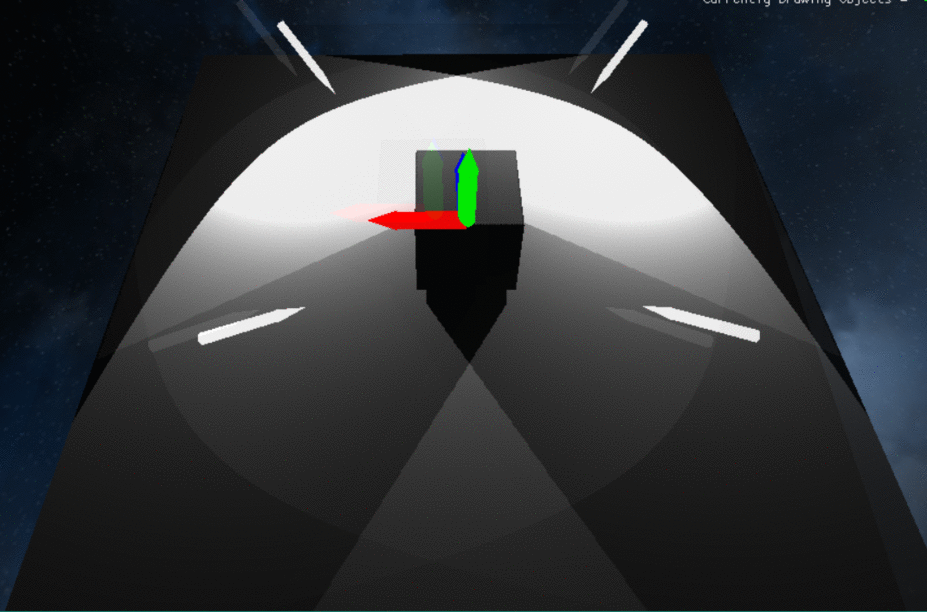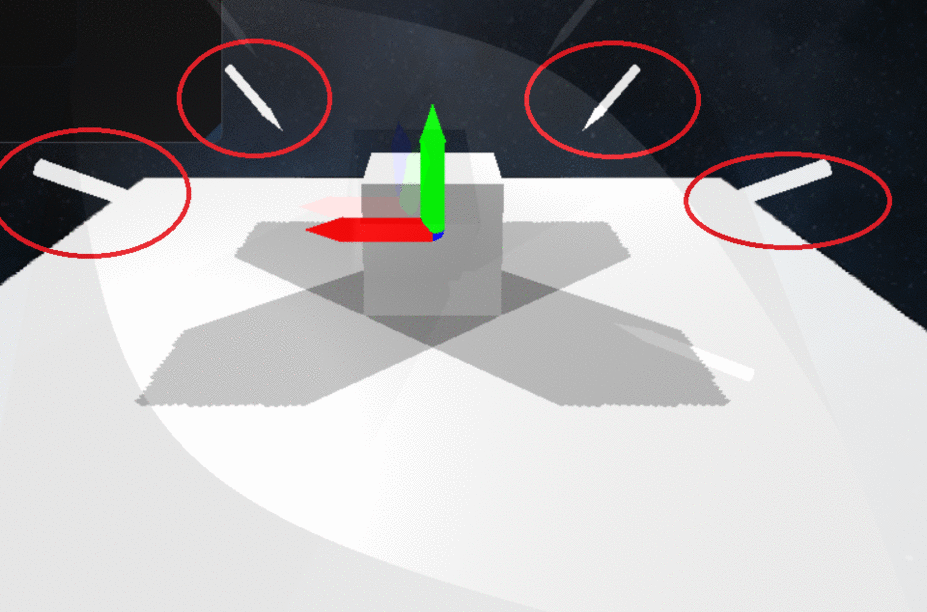
Demonstration of Multiple Directional Light and Spot Light Shadows
The Light Structure used for Lighting with or Without Shadows
Lighting With Shadows Fragment Shader Code
Method for Rendering Shadow Maps for all Shadow Casting Directional Lights.
-
There were a number of challenges getting shadow maps working. A major that still prevails is that the shadows suffer from artifacts like peter panning and shadow acne but the main focus of this project was optimization via multi threading and not on getting perfectly good shadows
Job System, Worker Threads and Atomic Mutex
-
The Job System is created as a global singleton and utilizes Total Number of Cores on the machine - 1 worker threads, minus 1 for the main thread.
-
Each Thread sets it's thread affinity mask over the cores to reduce resource contention and context switching.
-
The system is capable of handling child dependencies and indirect blocker dependencies on shared resources.
-
It follows a Lock free threading model using std::atomics.

Job System Worker Threads - Parallel Call Stack
Job System Worker Threads
The Job System - Overview
Atomic Mutex - a mutex created using atomics and Acquire and Release Semantics
(Reference - Which is more efficient, basic mutex lock or atomic integer?)
-
A great job system might be very much similar to an OS level scheduler and capable of supporting multiple type of Queues with Job Priorities and even giving the jobs fixed time slices and handling starvation and other such problems that arise from concurrency.
3-D Billboarded Particles
-
A 3-D billboarded particle system was implemented as a scalable inhibitor in conjunction with the shadow maps for testing performance limitations.
-
The particles are CPU instantiated, view frustum culled and billboarded.
-
The number of particles spawned per frame can be tuned as a controllable knob via the on screen UI.
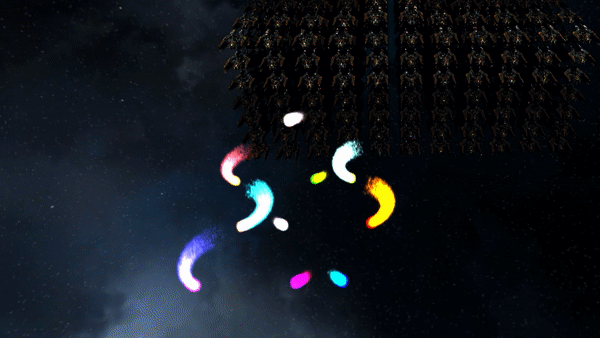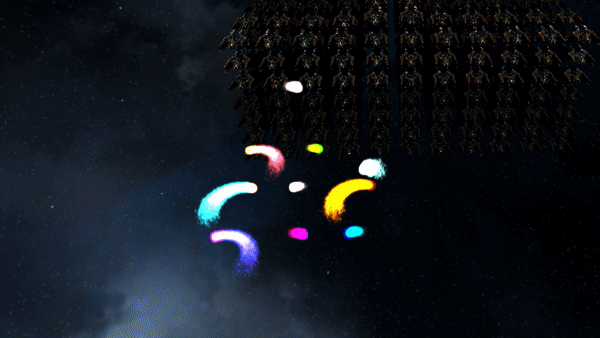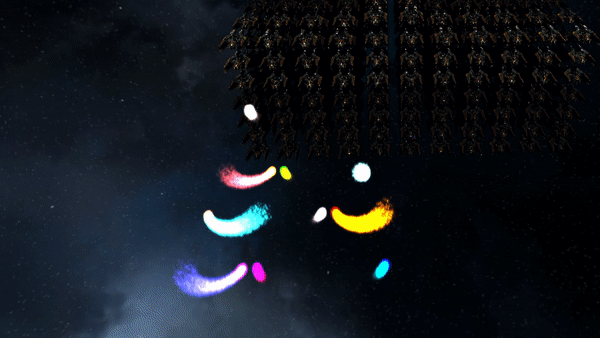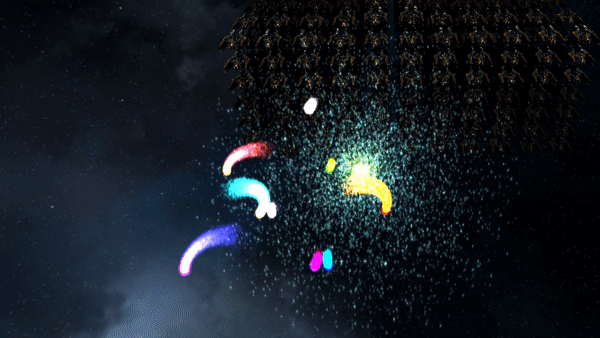
3D Billboarded Particles Demonstration
Particle Emitter 3D Data Members
3D Particle System
Particle 3D
Particle Optimizations, Limitations and Data Decomposition Models
Particles Spawning
-
Using a std::vector of particles on emitter turned out to be slow due to the dynamic memory allocations on the std::vector. So, the 3D particle emitter were switched to construction time fixed size array created dynamically once.
-
The fixed size array on the Particle Emitter 3D is treated like a Circular/Ring Buffer and the last position where the particle was spawned is cached off into the atomic variable - m_lastSearchPos.
-
A particle can only be spawned if space is available in the buffer.
-
Before starting to spawn particles a pre check is performed to see if a space is available for reuse another atomic variable - m_numAliveParticles is used to keep track of the number of alive particles against the buffer limit.
-
If pre check is passed another check is performed to find the slot available for reuse using a parallel array of atomic bools m_isParticleGarbage using the atomic exchange method on the slot index.
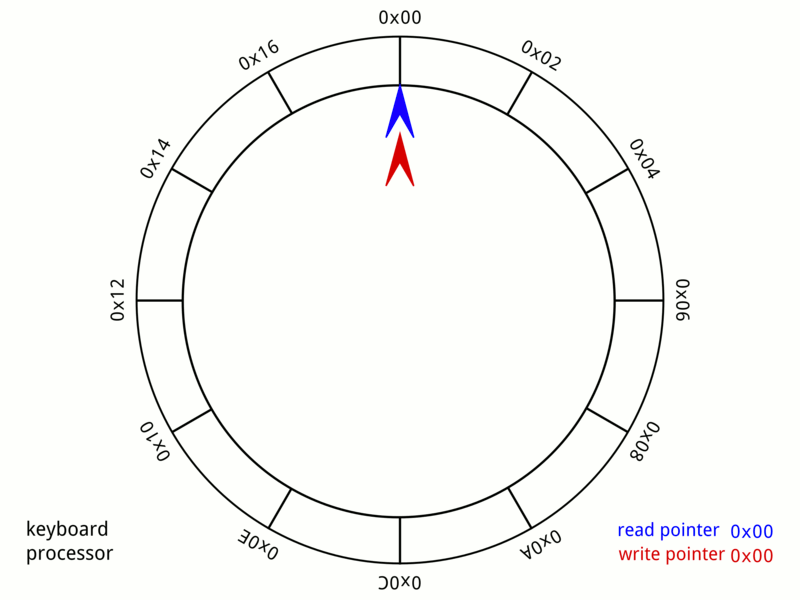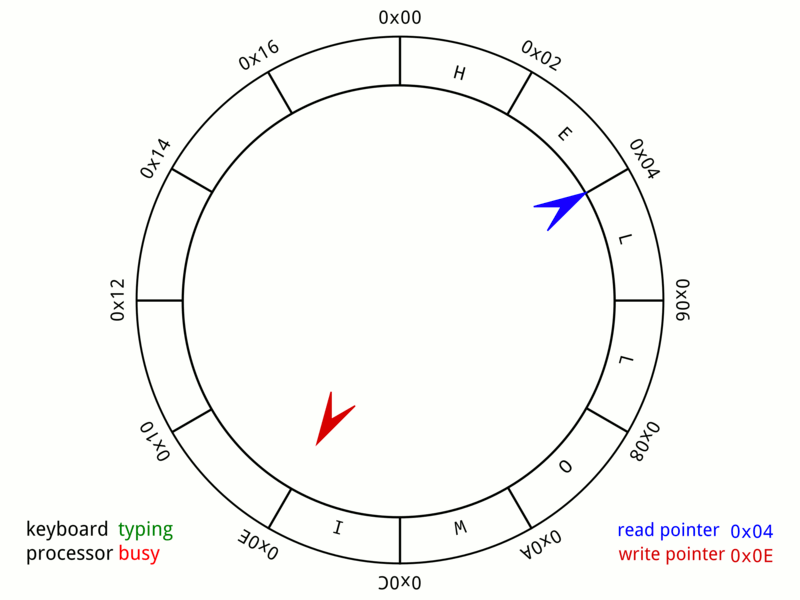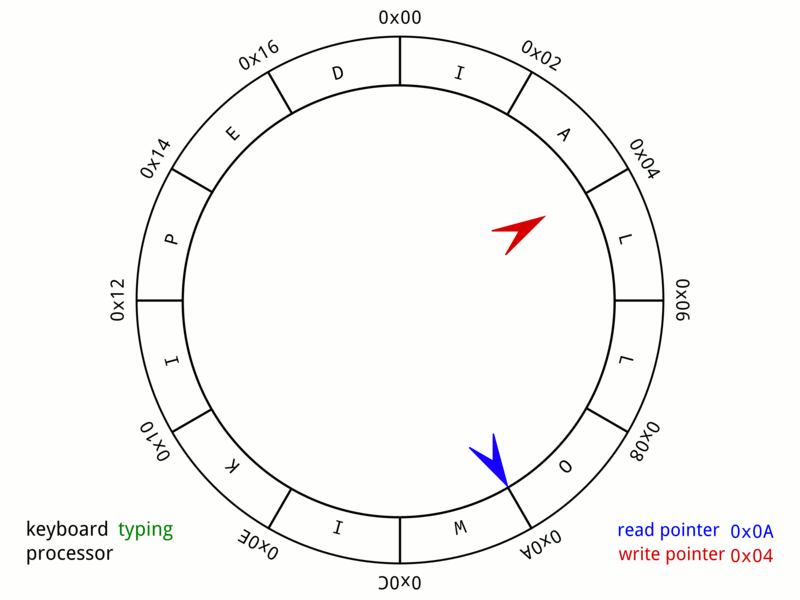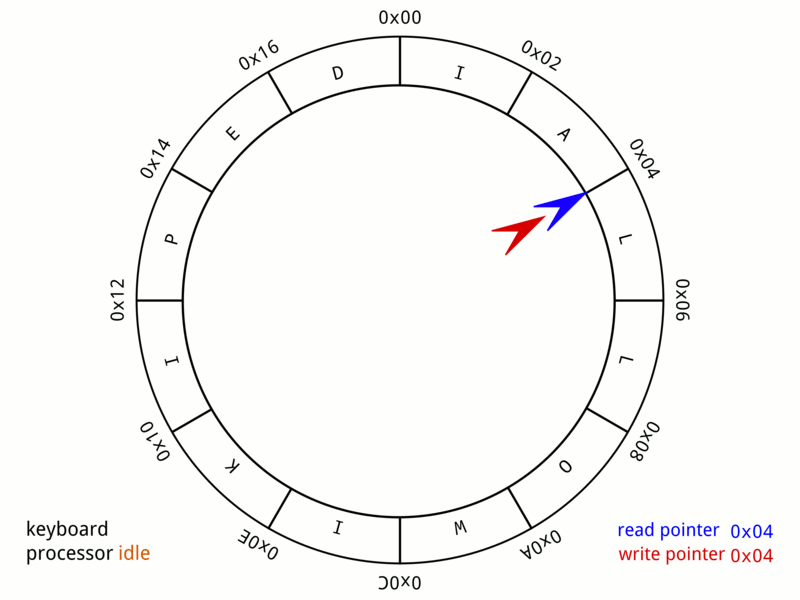
Particle 3D in a Circular/Ring Buffer on Particle Emitter 3D
(Image Source: Wikipedia - Circular_buffer)
Method to insert particles into the Circular/Ring Particle Buffer
Particles Data Decomposition Models
Model 1 - Game handles Particle Spawning Job while Engine handles the Update Job
-
In this model the game would post 1 or more Game Emitter Spawn Jobs to the Job System depending on number of emitter in the scene and their slot availability.
-
Each Game Emitter Spawn Job would spawn Emitter Spawn Sub Jobs based on Number of Particles to Spawn / Number of Cores - 1, minus 1 for the main thread and Number of cores - 1 is also the number of worker threads created by the jobsystem at startup.
-
These Spawn sub jobs are responsible for the actual spawning of the particles.
-
The job creates sub jobs every time for scalability with increase in number of particles over a single emitter.
-
While the Job System worker threads complete all the Particle Spawning Jobs, the main thread idle spins and waits for all of them to complete while checking constantly if they are complete.
-
After the spawning jobs are completed, the main thread would post a new particle system job which would post a new emitter update Job for every emitter it owns.
-
The Emitter Update Job will update the age, position, color, view frustum culling etc. of the particles in the particle buffer on the emitter.
-
Once the updation of the particle buffer is complete the Emitter Update Job Would Spawn new Create Particles Vertices Job similar to the Game Emitter Spawn Job i.e. Number of Particles in the view frustum / Number of Cores - 1, minus 1 for the main thread and Number of cores - 1 is also the number of worker threads created by the jobsystem at startup.
-
The major reason for again splitting Emitter Update Job into Particle Vertices Sub Jobs was the time consuming Billboarding calculations for the tens to hundreds of thousands of particles on a single emitter.
-
For efficiency and lock-free threading model with use of any synchronization primitives, the particle vertices sub jobs are divided using a divide and conquer, which means that the threads have access limited only to start and end index of the slots defined by the job they can access from the Particles Circular/Ring buffer.
-
The main thread needed to idle spin in this model because of the lack of support for job dependencies within the job system.

Particle System update dependency order with spin wait on Main thread

Particle System 3D Update Job
Model 2 - Game handles Particle Spawning Job And Game handles the Update Job
-
In this model the game would post 1 or more Game Emitter Spawn Jobs to the Job System depending on number of emitter in the scene and their slot availability.
-
Each Game Emitter Spawn Job in the constructor would spawn Emitter Spawn Sub Jobs based on Number of Particles to Spawn / Number of Cores - 1, minus 1 for the main thread and Number of cores - 1 is also the number of worker threads created by the jobsystem at startup.
-
These Spawn sub jobs are responsible for the actual spawning of the particles and the Emitter Spawn Job is dependent on the completion of the sub jobs in spawned.
-
The job creates sub jobs every time for scalability with increase in number of particles over a single emitter.
-
Once all Spawn sub jobs are completed the Game Emitter spawn job is ready to be executed and in it's execution it spawns an Update Emitter Job.
-
The Update Emitter Job then follows the same execution and communication flow as Model 1.
-
This dependency based model where the job system handles the dependencies helps in reducing the amount of Main thread idle Spinning.

Particle Emitter spawn and update dependency based jobs
Particles Tighter Data Packing
-
The original Particle 3D data structure used 80 bytes per particle i.e. on a L1 Cache of 64 KB a total of 819 particles could be loaded at once.
-
The Particle 3D data structure was updated to use 60 bytes per particle by making the following changes -
-
Is garbage and is view frustum culled boolean moved to emitter as arrays parallel to the particle array.
-
Age variables changed from float to uint16_t. Age now calculated in terms of frame count as opposed to time.
-
UV's stored as a sprite index integer as opposed to 4 floats for UV mins and maxs.
-
-
On a L1 Cache of 64 KB a total of 1092 particles could now be loaded at once.
-
This is a big improvement when you have tens or hundreds of thousands of particles in the scene as more data will now be cache warm or cache local.

Size and Alignment of initial implementation of Particle 3D

Size and Alignment of updated implementation of Particle 3D for tighter data packing
Original Data members in initial implementation of Particle 3D
Data members in final implementation of Particle 3D for tighter data packing
Particle Limitations
-
Only additive blending is supported at present.
-
A Particle can have last a maximum lifetime of 65535 frames i.e. at 60 FPS they can have a max lifetime of 18.2 seconds.
-
Do not support lighting or physics.
-
Any emitter particle buffer limit cannot be resized post construction.
Other features
-
View frustum culling has been implemented as one of the optimization techniques.
-
Screen Space post processing effects like tone mapping such as grayscale and sepia have been implemented via the pixel shader and compute shader for the purposes of performance analysis.
-
XML based data driven scene setup support for the following :-
-
Lights settings for all lights
-
Player Camera start Position
-
Models to load
-
Model Instances
-
Particle Emitter placements and effect settings
-
Scene startup settings and multithreading parameters
-
-
Minor features include switching to debug shaders such as UV, surface normals, vertex tangents, bitangents and more at run time via the UI.
-
Some other effect shaders supported are Triplanar, Fresnel and Discard shader.
-
Integration of Dear ImGUI for on screen UI.
-
Frame Rates and Frame time are plotted over 2.5 mins of playtime and rolled over using the ImGUI Implot extension library integration.
-
ImGUI File Dialog extension library was also integrated to support file dialog boxes and run time file loading and testing of certain features.
Multithreading Models, Profiling, Tracking Memory Leaks and Data Dumping
Multithreading Models and Profiling
-
Choosing the right profiler was one of the hardest tasks as Nvidia N-sight and Intel V-Tune did not support for instrumented profiling CPU and GPU simultaneously to the fine scaled granularity that was needed. They also had a lot more overhead than what was expected.
-
An open source profiler - Tracy Profiler was selected after testing various profilers, as it allowed fine grained instrumented profiling on both the CPU and the GPU.
-
2 Single threaded and 2 multithreaded models were profiled with the same scene setup as demonstrated in the demo.
Model 1 - Single Threaded Interleaved Update and Render loops

Single Threaded Interleaved Update and Render Loop Model
-
This is the Single threaded interleaved Update and Render model.
-
In this model we complete all the frame updates first and only then we start rendering.
-
Performance in this model is the worst of all models.
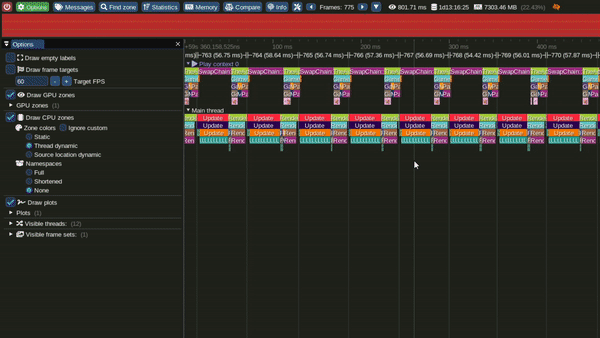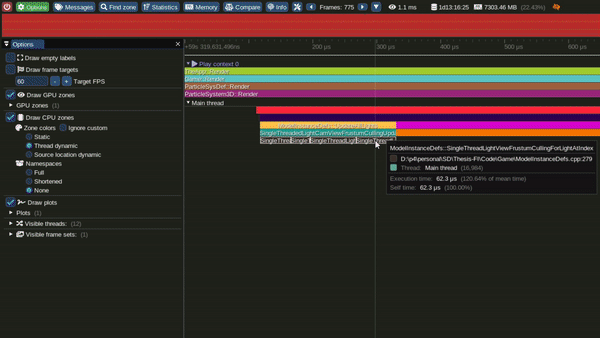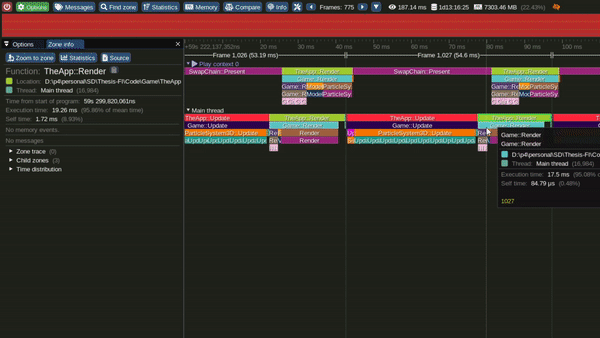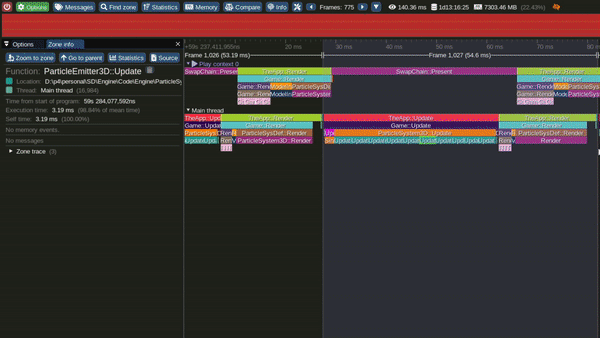
Tracy Profile Capture for this Model
Model 2 - Single Threaded Interlaced Update and Render loops

Single Threaded Interlaced Update and Render Loop Model
-
This is the Single threaded interlaced Update and Render model.
-
In this model we once we are done updating something, we immediately push rendering commands for that part of the loop.
-
It can also be observed that, in this model the GPU becomes busy much earlier in the frame.
-
Performance in this model was observed to be better than the interleaved model.
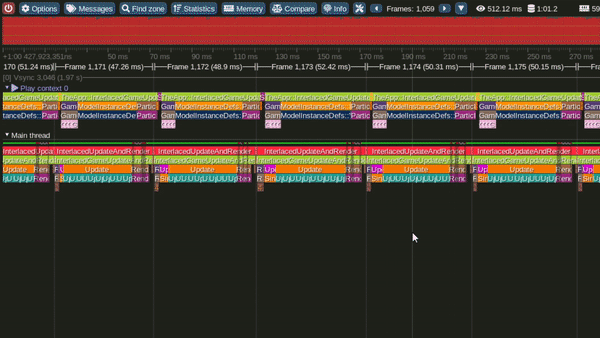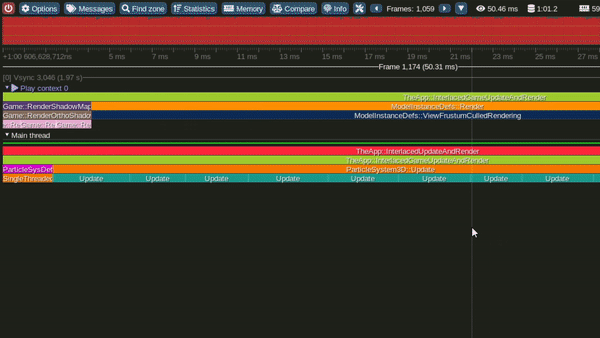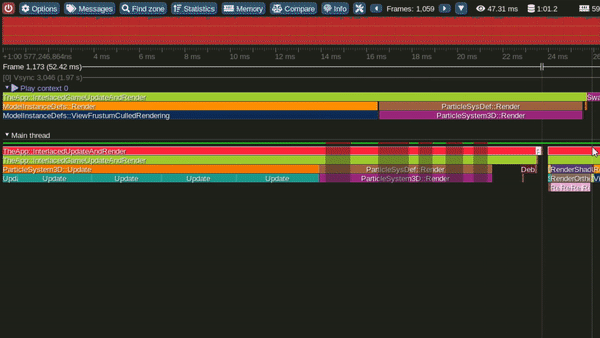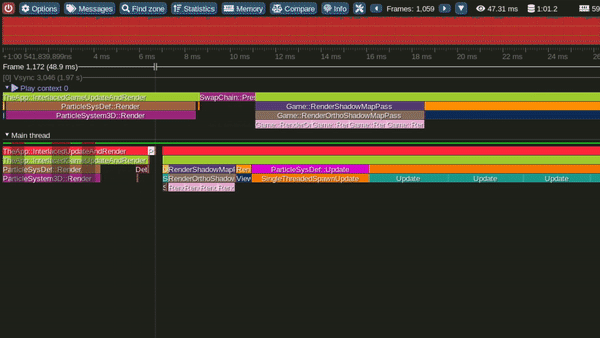
Tracy Profile Capture for this Model
Model 3 - Multithreaded Interleaved Update and Render loops

Multi Threaded Interleaved Update and Render Loop Model
-
This is the Multithreaded interleaved Update and Render model.
-
In this model we update light view frustum culling, particles over 1 or more emitters and player camera view Frustum culling over multiple threads concurrently. Once all updates are completed we start rendering.
-
Update starts again once present is completed.
-
It can also be observed that, in this model the GPU becomes busy much earlier in the frame.
-
Performance in this model was observed to be significantly better than the Single threaded interleaved and the Single threaded interlaced models.
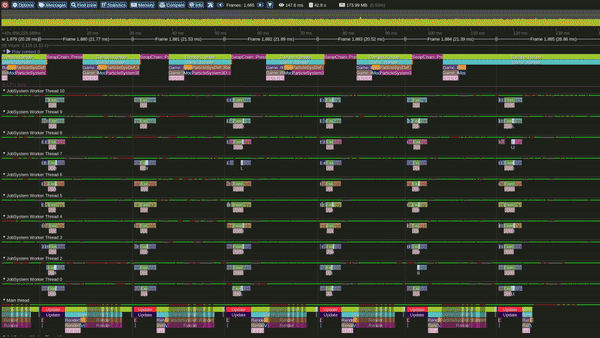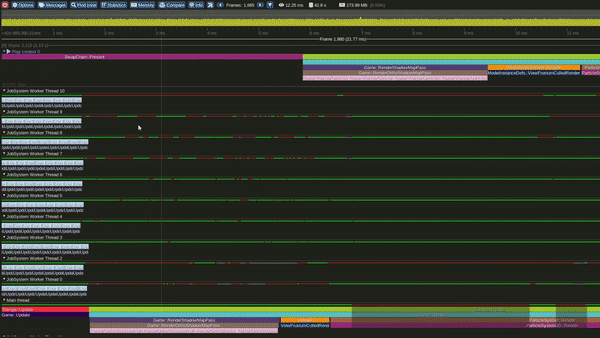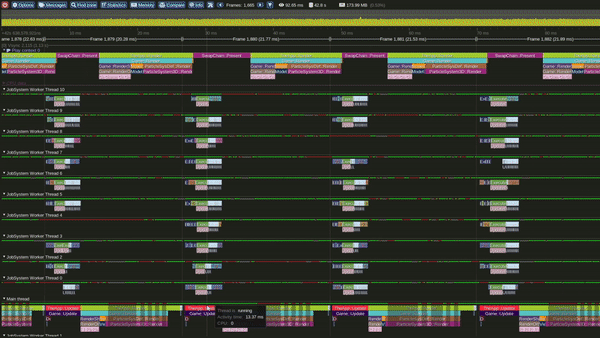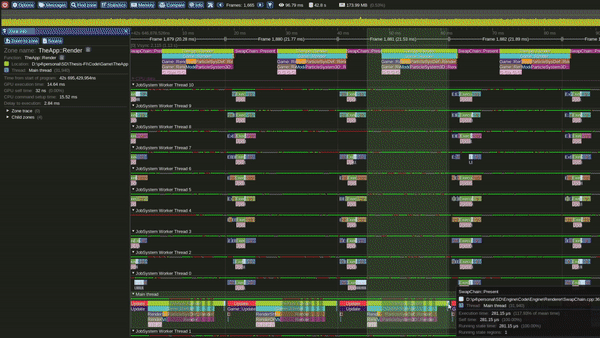
Tracy Profile Capture for this Model
Model 4 - Multithreaded Interlaced Update and Render loops

Single Threaded Interlaced Update and Render Loop Model
-
This is the Multithreaded interlaced Update and Render model.
-
In this model we update light view frustum culling via a worker thread and signal the main thread to render the shadow map once a culling job on a light is completed.
-
Similarly particles over 1 or more emitters are concurrently updated and upon completion signal the main thread and player camera view Frustum culling over multiple threads concurrently.
-
It can also be observed that, in this model the GPU becomes busy much earlier in the frame.
-
This model has a lot of dependencies and state blockers.
-
Performance in this model was observed to be significantly better than the Single threaded interleaved and the Single threaded interlaced models. It also performs very competitively against the Multithread interleaved model.
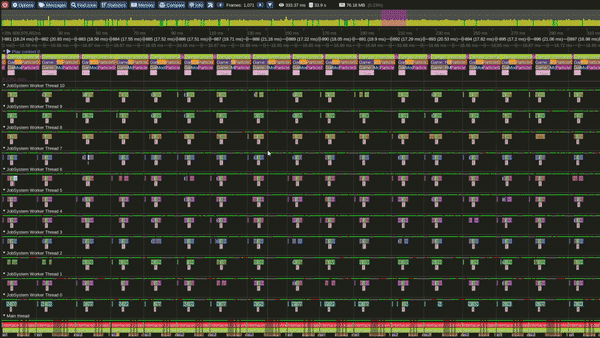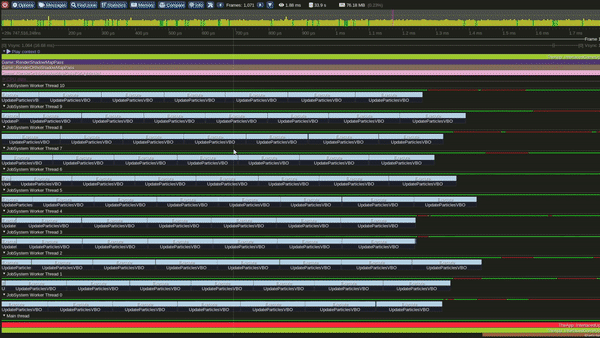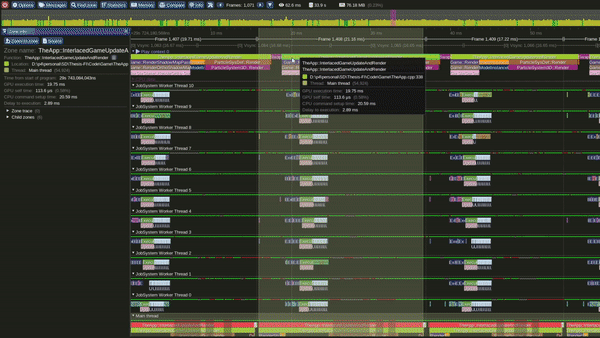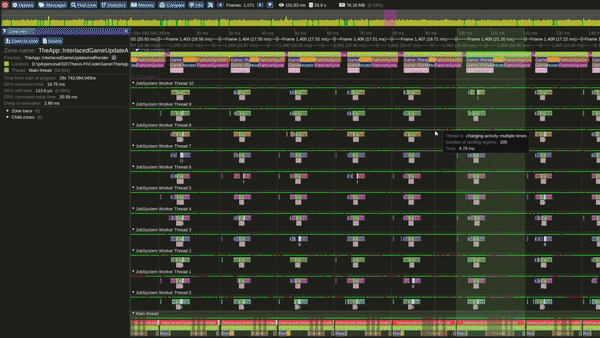
Tracy Profile Capture for this Model
Tracking Memory Leaks
-
Visual Studio Diagnostic Tools was used to track if there were any memory leaks by taking memory usage snapshot at the start of the program while the program was running and right before exiting the program.
-
Deleaker a C++ memory leak detection and tracker Visual Studio plugin was also used occasionally.
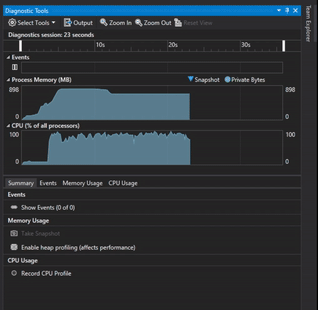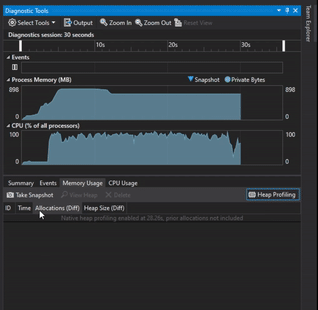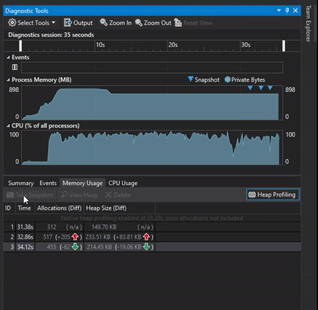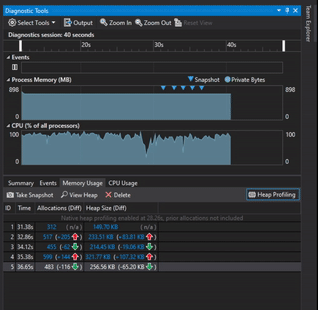
Tracking Memory with Visual Studio Diagnostic Tools
Tracking Memory with Deleaker
Development Insights and Deep Learning
-
A well behaved program does not need to change it's process class and thread priorities assigned to it by the Operating System.
-
Lockless or Lock free programming is less effective as compared to algorithms. - Fedor Pikus CPP Con 2017
-
A great Job System is almost very similar to an OS level scheduler.
-
Async bugs are hard to track due to varying timing of execution on the threads.
-
Typing the Release and acquire semantics help convey the intent more clearly than simply using the default values.
-
Thread memory leaks were easier to track because of the exponential increase in memory footprint.
-
There is no easy way to choose between different profilers and debuggers, but they have their use cases.
Post Mortem
What Went Well ?
-
Most features that were originally planned were accomplished.
-
Understanding of Low level programming and OS increased.
-
Data Driving helped save time on future iterations.
What Went Wrong ?
-
Debugging took longer than expected due to assumptions.
-
Decision on certain features could have been made earlier.
-
Until XML based data driving was added iteration on the scene setup was hard.
What I Learned ?
-
Go in assuming as little as possible - let the data tell you where to look.
-
Don't write optimized code all the time - but write optimizable code.
-
Using the right tool for the right job.
